Service Discovery
현재 저희 팀에서는 수동적인 배포 프로세스를 통해서 서비스를 배포 해오고 있었습니다. 수동적인 배포 프로세스로 인해서 개발자의 생산성이 저하되고, 간혹 실수가 발생하여 안정적으로 서비스를 제공하는데 있어 어려움이 있다고 판단되어 자동배포 프로세스를 구축을 진행하고 있습니다. 사내에서 자동배포 프로세스를 구축하면서 Service Discovery에 대해서 처음 접하게 되면에 Service Discovery에 대해서 공유하는 글을 작성하게 되었습니다.
해당 글은 Service Discovery in a Microservices Architecture를 토대로 개인적인 견해를 정리한 글입니다.
Service Discovery를 사용하는 이유는 무엇일까?
REST API를 통해 서비스를 호출 해야 한다고 가정해 보도록 하겠습니다. 서비스로 요청을 하려면 우리는 서비스 인스턴스의 네트워크 주소(IP주소 와 포트)를 알아야 합니다. 기존의 레거시 방식에서는 서비스의 네트워크 주소가 변경될 일이 적었고 배포 주기 또한 길었기 때문에 네트워크 주소를 수동적으로 수정하는 방식을 많이 사용하였습니다. 그러나 최근에 클라우드 환경이 추세가 되면서 서비스 아키텍처 구조는 점점더 세분화 되어 지고, 배포 주기 또한 짧아졌기 때문에 기존의 수동적으로 수정하는 방식을 고수하기란 불가능해 졌습니다.
서비스 인스턴스가 많을수록 미리 정의된(고정적인) 포트를 사용한다면 충돌 될 가능성이 많아집니다. 그렇기 때문에 우리는 포트를 지정하지 않고 서비스를 배포하고, 도커가 임의로 할당하도록 인프라를 구성해야 합니다. 물론 포트를 미리 정의해서 구성할 수도 있겠지만 이런 구성은 문제를 야기시킵니다. 서비스의 자동 확장이 어려워 지고, 장애로 부터 자가 치유가 어려워 집니다.
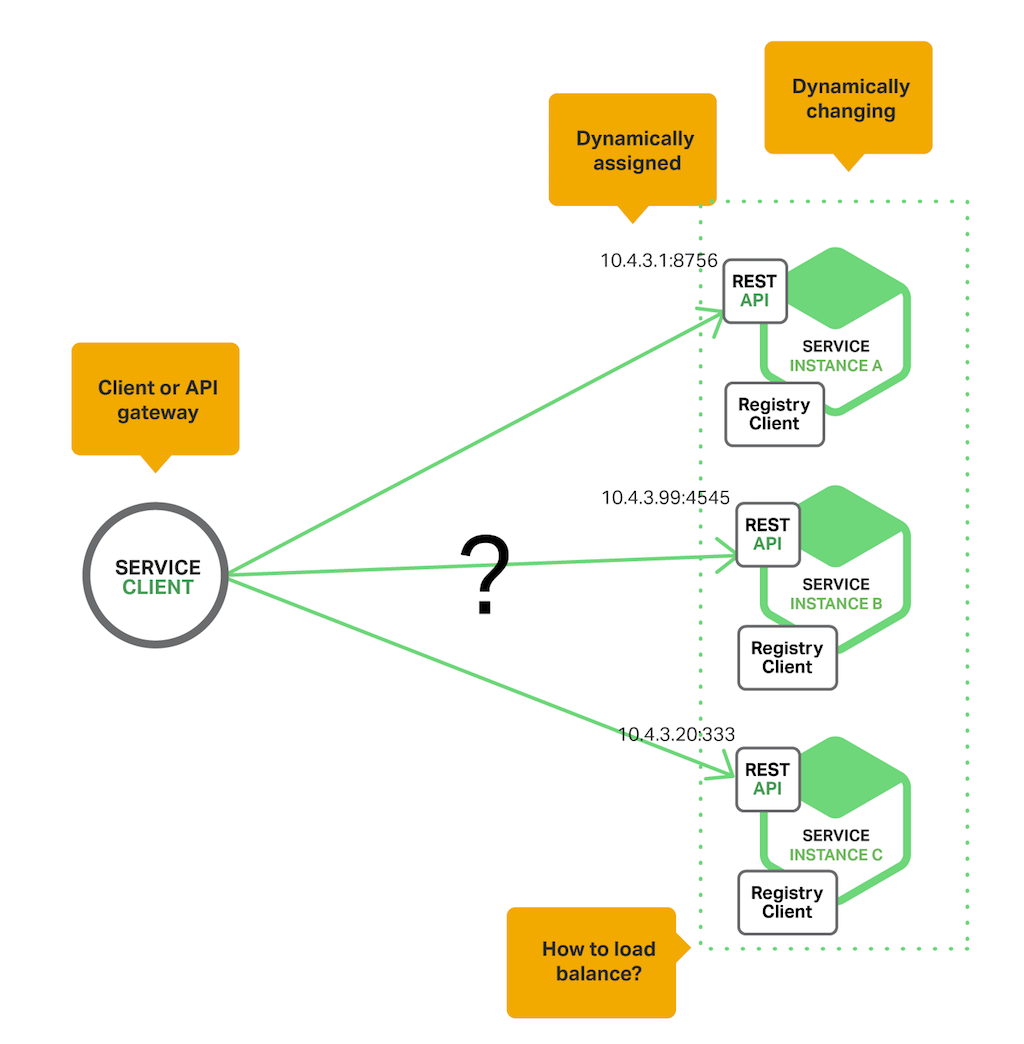
서비스 인스턴스에는 네트워크 주소가 동적으로 할당됩니다. 또한 서비스 인스턴스 집합은 자동 확장, 해지 및 최신 버전 배포 등으로 네트워크 주소가 동적으로 변경되어야 합니다.
서비스 클라이언트(클라이언트 혹은 API 게이트웨이)는 서비스 인스턴스를 호출하기 위해 동적으로 할당되는 서비스 인스턴스의 네트워크 주소를 찾아낼 수 있어야 합니다. 두 가지 Service Discovery Pattern이 있습니다.
Client‑Side Discovery Pattern
클라이언트는 사용 가능한 서비스 인스턴스의 네트워크 주소를 찾고, 로드 밸런싱 된 요청을 보내는 일을 담당합니다. 클라이언트는 사용 가능한 서비스 인스턴스의 네트워크 주소를 Service Registry에게 요청합니다. 추후 Service Registry에 대해 다룰 예정이므로 간단하게 서비스 인스턴스의 네트워크 주소를 저장하는 저장소라고 생각하시면 될거 같습니다.
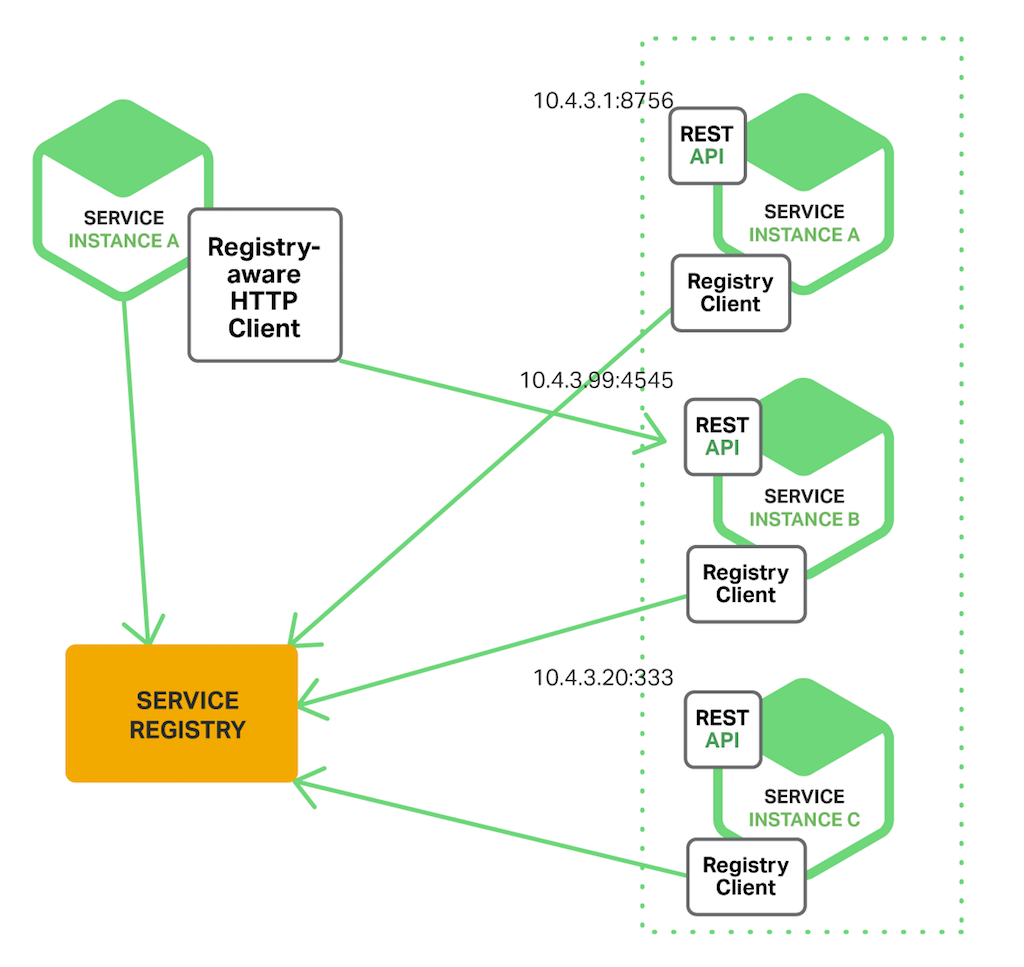
서비스 인스턴스가 시작될 때 서비스 인스턴스의 네트워크 주소를 Service Registry에 등록합니다. 서비스 인스턴스가 종료되면 Service Registry에서 제거합니다. 일반적으로 HeartBeat 메커니즘을 사용하여 서비스 인스턴스를 주기적으로 검사 및 최신 상태로 반영합니다.
Client‑Side Discovery Pattern에는 다양한 장점과 단점이 존재합니다.
장점
- 비교적 간단하다.
- 클라이언트가 사용가능한 서비스 인스턴스를 알고 있기 때문에, 서비스 인스턴스 별로 알맞은 로드밸런싱 방법을 선택할 수 있다.
단점
- 클라이언트와 Service Registry의 높은 결합도
- 서비스 클라이언트가 Service를 Dicsovery 하는 로직은 직접 구현해야 한다.
이제까지 클라이언트 측 검색을 살펴보았습니다. 서버 측 검색을 살펴 보겠습니다.
Server‑Side Discovery Pattern
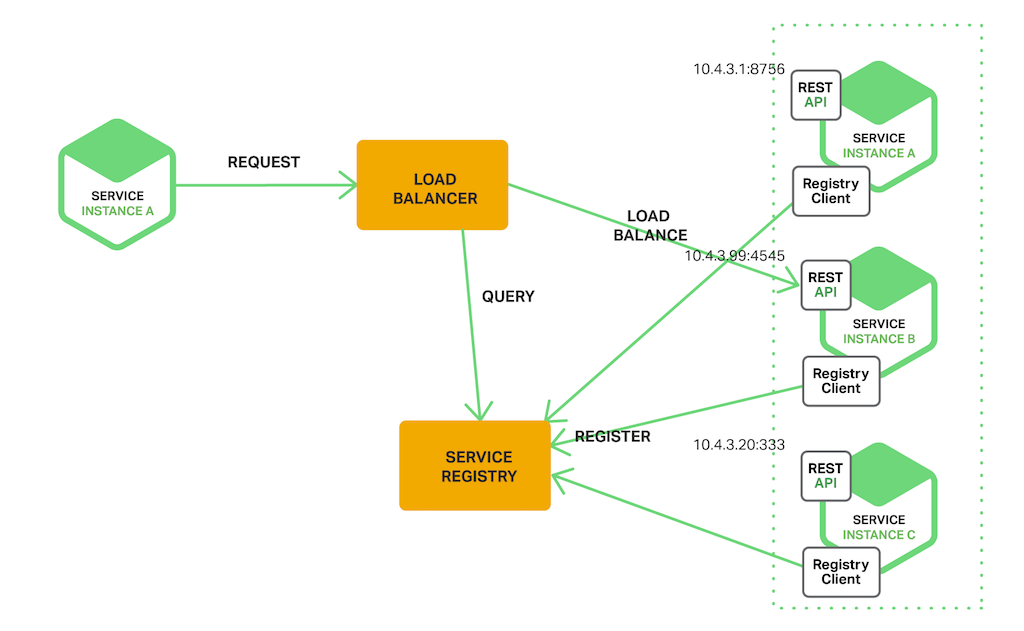
클라이언트는 로드 밸런서를 통해서 서비스에 요청합니다. 로드 밸랜서는 Service Registry에서 각 요청에 대해 사용 가능한 서비스 인스턴스의 네트워크 주소를 질의하고 반환 된 네트워크 주소로 라우팅 합니다. 클라이언트 측 검색과 마찬 가지로 서비스 인스턴스는 Service Registry에 등록 및 해제 됩니다.
Server‑Side Discovery Pattern 또한 다양한 장점과 단점이 존재합니다.
장점
- discovery 세부 사항을 클라이언트에서 분리할 수 있다.
- 클라이언트는 단순히 로드밸런서에 요청만 한다.
- 서비스 클라이언트가 Service를 Discovery 하는 로직을 구현할 필요가 없다.
단점
- 배포환경에서 로드밸런서를 구축해야 한다.(대부분의 운영환경에서 로드밸런서를 구성하기 때문에 큰 단점이 라고는 생각하지 않습니다.)
Service Registry
Service Registry는 Service Discovery 에서 매우 중요한 부분입니다. Service Registry는 간단하게 말하자면 동적으로 생성되는 서비스 인스턴스의 네트워크 주소를 저장하는 저장소 입니다.
Service Registry 개념에 대해서 살펴보았습니다. 서비스 인스턴스가 Service Registry에 등록되는 방법에 대해서 살펴 보도록 하겠습니다.
Service Registration Options
앞서 언급했듯이 서비스 인스턴스는 Service Registry에 등록/해지 되어야 합니다.
등록/해지를 처리하는 몇가지 방법이 존재합니다.
Self‑Registration Pattern
서비스 인스턴스가 Service Registry에 등록/해지의 책임을 가집니다.
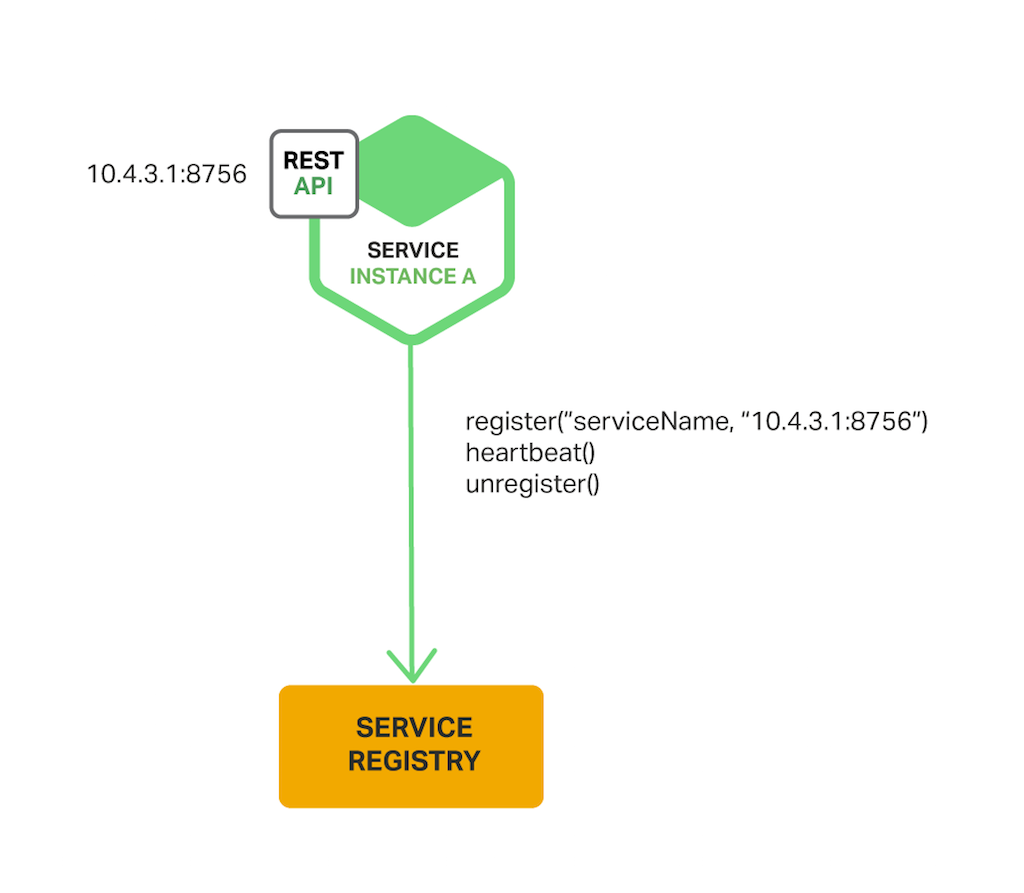
Self-Registration Pattern 에는 다양한 장점과 단점이 존재합니다.
장점
- 비교적 간단하다.
- 별도의 시스템 컴포넌트가 필요로 하지 않다.
단점
- 서비스 인스턴스와 Service Registry의 높은 결합도
- 서비스 인스턴스에서 Service Registry에 등록/해지 관련 로직은 직접 구현해야 한다.
- 정상적이지 않은 종료가 발생할 경우 안정성을 보장하지 않는다.
Third‑Party Registration Pattern
서비스 인스턴스가 Service Registry에 등록/해지의 책임이 없습니다. 대신 Registrar가 이를 수행합니다.
Registrar는 실행 중인 서비스 인스턴스에 폴링하거나 이벤트를 구독하는 등의 작업을 통해 변경 사항을 감지하고 Service Registry 등록/해지를 수행합니다.
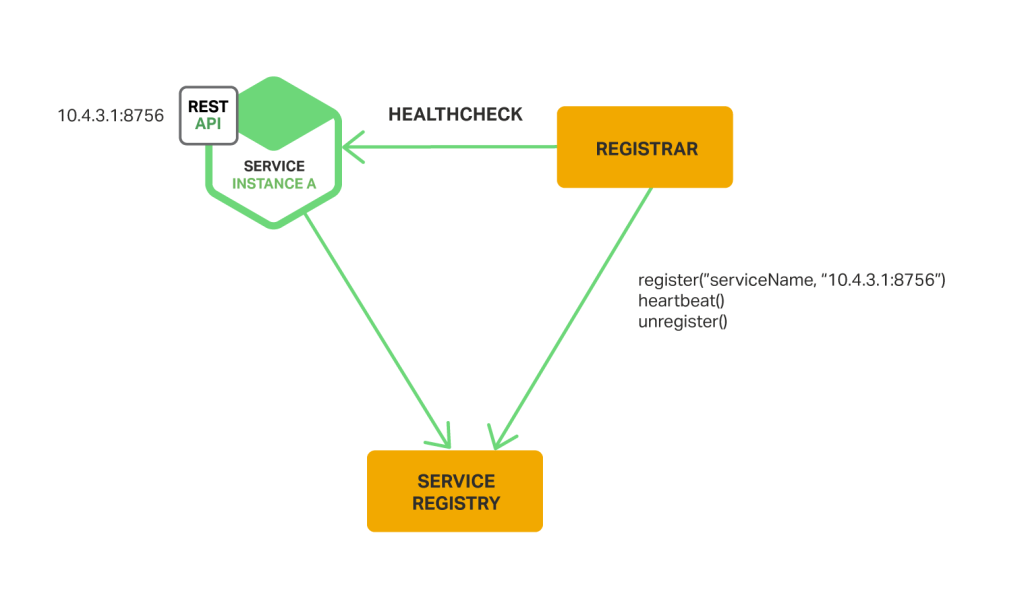
오픈소스로 Registrator 오픈 프로젝트가 있습니다. Docker 컨테이너로 배포 된 서비스 인스턴스를 자동으로 등록/해지 할 수 있습니다. Registrator 는 etcd 또는 Consul을 포함한 여러 Service Registry를 지원합니다.
Third‑Party Registration Pattern 에는 다양한 장점과 단점이 존재합니다.
장점
- 서비스 인스턴스와 Service Registry의 낮은 결합도
- 서비스 인스턴스에서 Service Registry에 등록/해지 관련 로직을 구현할 필요가 없다.
- 정상적으로 서비스 인스턴스가 종료되었더라도 높은 안전성을 보장한다.
단점
- 서비스 인스턴스의 동록이 중앙 집중식으로 처리된다.
- 시스템 컴포넌트 관리에 따른 관리 포인트가 추가됩니다.
Reference
- https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture
댓글남기기